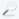 SİTE
İÇİ ARAMA SİTE
İÇİ ARAMA |
|
|
 Blogroll Blogroll |
|
|

|
|
|
|
MPI ile Paralel Programlama - 2 |
|
| Gönderiliyor lütfen bekleyin... |
|
|
Geçen yazımızda MPI ile programlamaya bir giriş yapmıştık ve 12 bilgisayarın her
birinden “merhaba dünya” yazısını yazdırmıştık. Bu yazımızda MPI haberleşme
fonksiyonlarını inceleyeceğiz. MPI haberleşme fonksiyonları MPI kütüphanesinin
belkemiğini oluşturan fonksiyonlardır.Yapmak istediğimiz hesaplara ve
algoritmalara bağlı olarak değişik haberleşme fonksiyonları kullanmamız
gerekecektir. Şimdi MPI de en çok kullanılan ve bilinen haberleşme
fonksiyonlarımıza geçelim (Çok fazla fonksiyon olduğundan en önemlilerini
incelemeye çalışacağız.)
En önemli
haberleşme fonksiyonlarımız Send ve Recv fonksiyonlarıdır. Çoğu paralel prosesler Send ve Recv fonksiyonlarının
dışında fonksiyon kullanmazlar. Bu fonksiyonların en önemli özelliği verileri ara belleklere
hangi proses tarafından isteniliyorsa o prosese doğru bir şekilde iletmeleridir. Bu
işlem için buffer dediğimiz arabellek alanı kullanılmaktadır. Bu
fonksiyonlar veriyi önce prosesin arabelleğine göndermekte ve o proses üzerine alana
kadar bu verinin üzerine başka veri yazmamaktadır. Aynı şekilde veriyi almaya
gelen fonksiyon da o veriyi alana kadar beklemekte ve aldıktan sonra söz konusu
arabelleği boşaltmaktadır. Dolayısı ile Send/Recv fonksiyonları sayesinde veriler kaybolmamaktadır.
Aşağıdaki
çizimde makineler arası Send/Recv
fonksiyonlarının nasıl çalıştığını görmektesiniz. Örneğimizde de send/recv fonksiyonlarını
kullanacağız.
MPI_SEND(&buffer,count,datatype,dest,tag,comm)
MPI_RECV(&buffer,count,datatype,source,tag,comm,status)
Fonksiyonlarımız burada değişik parametreler almaktadır
bunlardan buffer yollanacak veya alınacak verinin
adresini göstermektedir. Count parametresi yollanacak verilerin
sayısını belirtmektedir. Datatype parametresi gidecek verinin
türünü belirtmektedir (int,float,char,...). Dest parametresi verinin hangi makineye
gideceğini
belirtmektedir. Source parametresi verinin hangi makineden
alacağını belirtmektedir.Tag parametresi ise 0-32767 arası sayısal bir değer
alır ve
kullanıcı tarafından yanlış makinelerden mesajlar gelmesini önlemek için verilebilecek
bir tür güvenlik kodudur. SEND ve RECV fonksiyonlarında tag lerin
eşit olması gerekmektedir.Comm değişkeni olarak
genelde MPI_COMM_WORLD kullanılmaktadır. Grup haberleşme fonksiyonlarında
değişik “comm” değerleri kullanılmaktadır. Şu anlık bu
değer yeterlidir. Grup haberleşme fonksiyonlarında ise comm
parametresi birden fazla değer alabilir. En son parametre değerimiz ise RECV
fonksiyonundaki status değeridir. Status
mesajın geldiği kaynağı bize bildirmektedir.
SEND/RECV
fonksiyonlarımızın dışında işimize yarayabilecek başka fonksiyonlarda vardır
bunları kısaca inceleyecek olursak;
MPI_ISEND(&buffer,count,datatype,dest,tag,comm)
MPI_IRECV(&buffer,count,datatype,source,tag,comm,status)
Yukarıda
gördüğünüz komutların Send ve Recv
fonksiyonlarından tek farkı “I” (Immediate) yani
beklemeksizin veri alışverişlerin olmasıdır. Sizin de tahmin edebileceğiniz
gibi, Send/Recv fonksiyonlarında var olan
otomatik olarak bekleme işlemi burada kullanıcı inisiyatifine bırakılmaktadır. Bu fonksiyonlar tek başlarına kullanılmazlar.
Muhakkak MPI_WAIT veya
MPI_TEST gibi yardımcı fonksiyonları kullanmaları gerekmektedir.
MPI_WAIT(&request,&status)
ISEND ve IRECV fonksiyonları verileri yollayana veya
alana kadar beklemelerini sağlayan fonksiyondur. Status
istenilen mesajın adresini ve tag ini dönmektedir.
MPI_TEST (&request,&flag,&status)
Bu
fonksiyonumuz da istenilen verinin ulaşıp ulaşmadığını kontrol etmek için
kullanılır. Eğer verimiz istenilen yere ulaşmışsa flag
olarak true değeri dönmektedir.Status
istenilen mesajın adresini ve tag ini dönmektedir.
MPI_REDUCE(data, result, count, type, op, root,comm)
Bu fonksiyonumuz N tane makinede oluşmuş sonuçları derleyerek ana proses te result dizisinde
saklamaktadır.
Geri kalan değişkenlerden count “reduce”(alınmış veri) sayısını, type alınan verilerin türlerini, op
yapılan alınma işlemlerinin sonuçlarını, root verilerin alındığı prosesleri ve
son olarak comm haberleşme ortamının adını (MPI_COMM_WORLD) almaktadır.
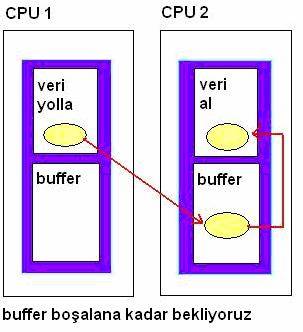
Bu yazdıklarımızı bir de görsel olarak açıklayalım.
Yukarıda da gördüğümüz gibi 5 tane işlemci ayrı data yani veriler üretmektedir. İstersek bunları ayrı
ayrı yollayabiliriz. Bunun için her makine send/recv fonksiyonlarını kullanabiliriz. Biz bunun yerine MPI_REDUCE fonksiyonunu kullanıyoruz.
Elimizde ki bütün “data” verilerini MPI_REDUCE aracılığı ile ana işlemcide “result” dizisine gönderiyoruz.
MPI_ALLREDUCE(data, result, count, type, op, root,comm)
ALLREDUCE fonksiyonu REDUCE ile işlevsel olarak aynıdır.
Tek farkı bütün proseslere result değerini göndermektedir.
MPI_BARRIER(comm)
Global haberleşme fonksiyonlarının en önemlilerindendir.
Bütün proseslerin işlemleri tamamlanana kadar devam etmelerini engelleyen senkronizasyon fonksiyonudur.
MPI_BCAST(&buffer,count,datatype,root,comm)
BCAST, Broadcasting kelimesinin kısaltılmış halidir. Root olarak sayılan prosesten arabellekteki (buffer) değerleri “comm” ortamında ki bütün proseslere yollamaktadır.
İlk yazımda yazdığım gibi MPI paralel makineler arası haberleşme kütüphanesidir ve 100 den fazla fonksiyonu vardır.
Yukarıda size sadece bu haberleşme fonksiyonlarının en çok kullanılanlarını verdim çok daha karışık amaçlar için kullanabileceğiniz
spesifik fonksiyonlar da vardır.UYGULAMA
Örnek olarak bu yazımızda integral değer
hesaplayan bir kod yazacağız. Integral
almak için 10 makine kullanacağız. Bunun için “trapezoidal” adı verilen bir yöntem kullanacağız. Paralel kodumuz burada integrali
hesaplanacak fonksiyonun X aralığa bölünerek her aralıkta integralin ayrı hesaplanmasından sorumlu olacaktır.
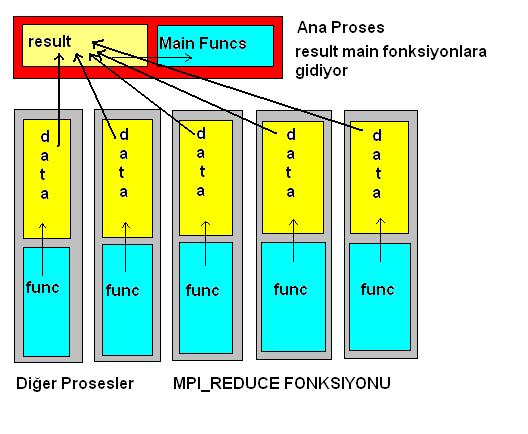
Fonksiyonu
dikdörtgenlere ayırarak alan hesaplamak : Trapezoidal
Amacımız matematik olmadığı için sizi matematiksel
yöntemleri anlatarak sıkmayacağım.Yukarıda da gördüğünüz gibi bir fonksiyonun altındaki alanı hesaplamak
için o fonksiyonu dikdörtgenlere bölüyoruz ve o
dikdörtgenlerin alanlarını hesaplıyoruz. Eğer dikdörtgen sayısı yeterince fazla
olursa (bizim örnekte 1000 olacak) dikdörtgenler neredeyse fonksiyona dönüşür
ve fonksiyonun alanına çok yakın bir değer elde ederiz.
Kodumuz
ise bu fonksiyonun altındaki alanı 10 parçaya bölüyor ve 10 bölgede 100 tane dikdörtgen
(toplamda 1000 tane dikdörtgen) oluşturarak bunların alanlarını hesaplıyor daha
sonra bütün değerleri toplayarak integrali veriyor. Şimdi geldik kod kısmına:
#include <stdio.h>
#include "mpi.h"
// f fonksiyonu f(x)=x*x*x-x*x kabul
edilmiştir
// verilen x değeri için f(x) değerini
vermektedir
float f(float
x);
// Yukarıda açıkladığım Trapezoidal kuralına uygun şekilde bize dikdörtgenlerin
alanını vermektedir //
float Trapezoidal(float aa, float
bb, int nn, float h);
int main(int argc, char**
argv)
{
int prosesrank;
int p;
// başlangıc
noktamız 5 bitiş noktamız 10 //
float a = 5.0;
float b = 10.0;
// 1000 tane dikdörtgen oluşturuyoruz
//
int n = 1000;
float h;
float aa;
float bb;
int nn;
float integral;
float toplam;
// MPI fonksiyonları için gerekli
değişkenler //
int source;
int dest = 0;
int tag =
50;
MPI_Status status;
// prosesler başlıyor //
MPI_Init(&argc, &argv);
// Rank
fonksiyonu ile bu kodun hangi makinede (proseste) olduğunu öğreniyoruz //
MPI_Comm_rank(MPI_COMM_WORLD, &prosesrank);
// Aşağıdaki fonksiyon bize proses
sayısını veriyor //
// bu fonksiyonlar hakkında bilgiyi ilk
yazımda bulabilirsiniz //
MPI_Comm_size(MPI_COMM_WORLD,
&p);
// b fonksiyonun sonu a başı bunu n
kadar yani 1000 kadar eşit parçaya bölüyoruz //
h = (b-a)/n;
// 1000 parçayı p prosese
paylaştırıyoruz //
nn = n/p;
// aa ve bb değerleri
bize prosesler tarafından paylaşılan aralıkların başını ve sonunu vermektedir
//
aa = a + prosesrank*nn*h;
bb = aa
+ nn*h;
// başı aa
sonu bb olan aralıkların alanlarını hesaplıyoruz //
integral = Trapezoidal(aa, bb, nn,
h);
// aşağıda ki kısımda 1. proses ( yani
0 ) bize sonuçları vermektedir //
// aşağıda ki kısım sadece 1.proses
için geçerlidir //
if (prosesrank
== 0)
{
toplam = integral;
// her prosesten Recv komutu ile ayrı
ayrı integral sonuclarını alıyoruz //
// dikkat edin burada IRecv fonksiyonunu
kullanamıyoruz çünkü yukarıda da açıkladığım gibi gönderilmeye hazır değil Recv/Send ikilisi arabellekleri
kullanarak alınacak veri gelene kadar beklemektedirler //
for (source = 1; source < p; source++)
{
MPI_Recv(&integral,
1, MPI_FLOAT, source, tag,MPI_COMM_WORLD,
&status);
// MPI fonksiyonlarının güzelliğini
görüyorsunuz ! Sizden ayrı olarak bekleme komutları istenmiyor buffer da oluşacak değeri Recv
fonksiyonu kendisi otomatik olarak oluşunca alıyor //
toplam += integral;
}
}
// aşağıda ki kısım ise 1.proses
dışındaki bütün proseslerde geçerlidir //
// Yukarıda yaptığım fonksiyon
tanımlarına bakarsanız Send fonksiyonu kendi integral// // değerlerini 1.prosese yollamaktadır //
else
{
MPI_Send(&integral, 1,
MPI_FLOAT, dest,tag, MPI_COMM_WORLD);
// burada da integral değerleri
her makinenin bufferine yollanmaktadır,eğer diğer
makinenin Recv komutu ulaşmışsa anında alınmaktadır
eğer ulaşmamışsa o Recv fonksiyonu gelene kadar integral değeri o buffer da
beklemektedir //
}
// 1.prosesten sonucu yazdırıyoruz //
if (prosesrank
== 0)
{
printf("başlangıcı %f sonu %f olan fonksiyonun integrali = %f\n",a, b, toplam);
}
MPI_Finalize();
return 0;
}
/* Fonksiyonlarımız */
float f(float
x)
{
float sonuc;
sonuc=x*x*x-x*x;
return sonuc;
}
float Trapezoidal(float aa, float
bb, int nn, float h)
{
float integral;
float x;
int i;
integral = (f(aa)
+ f(bb))/2.0;
x = aa;
for (i = 1; i <= nn-1; i++)
{
x += h;
integral += f(x);
}
integral *= h;
return integral;
} |
Yukarıda
da gördüğünüz gibi Send/Recv
fonksiyonları kullanıcının wait, lock
gibi komutları kullanmadan prosesler arasında iletişimleri oldukça etkili bir şekilde
sağlamaktadır. Programı
çalıştırdıktan sonra aşağıdaki ekran görüntüsünü elde ederiz.
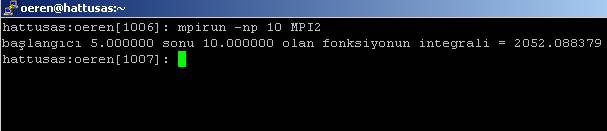
Eğer bu
alanı analitik olarak hesaplarsak sonucu 2052.0883.... olarak bulmaktayız.
Sonuç Olarak
Bu yazımızda
gördüğünüz gibi MPI ile prosesler arası iletişim cidden çok kolay ve
kullanıcılar limitleri çok zorlamadıkları sürece bir problemi daha küçük
parçalara bölerek çok kolay çözebilmektedir. Her ne kadar integral
örneğimiz basit bir örnek olarak kalsa da Send/Recv fonksiyonlarını ve diğer haberleşme fonksiyonlarını
rahatça daha büyük örneklerinizde kullanabilirsiniz. İleriki yazılarımda Paralel
Algoritmaları işleyerek bir işi 10-20 makinede yapmanın bize neden avantaj
sağladığını göstereceğim. Sağlıcakla kalın!
Özkan
Eren
[email protected]
Makale:
MPI ile Paralel Programlama - 2 C++ ve C++.NET dili Özkan Eren
|
|
|
|
|
-
-
Eklenen Son 10
-
Bu Konuda Geçmiş 10
Bu Konuda Yazılmış Yazılmış 10 Makale Yükleniyor
Son Eklenen 10 Makale Yükleniyor
Bu Konuda Yazılmış Geçmiş Makaleler Yükleniyor
|
|
|
|